HashMap 基本介绍#
HashMap 是 Map 接口中最为常用的一个实现类,通过名字我们可以看出,它与 hash 算法密不可分。它的内部用来存放键值对。HashMap 的底层实现是数组和链表 / 红黑树。
简单解释一下它的原理来加深自己的印象:HashMap 主要维护了一个数组,数组中存放的是 Entry 对象,该对象包含了 key(键)、value(值)、hashcode(key.hashCode() 返回的值) 以及 next(下一个 Entry 对象),我们的键 / 值对就是存放在一个个的 Entry 对象中。但是如果仅仅是这样,就与普通数组没什么区别了,插入和删除的效率都很低。为了提高效率,HashMap 还引入了链表。下面直接上一张图吧,画功不好,简单嘲笑一下后就接着往下看吧🙃。
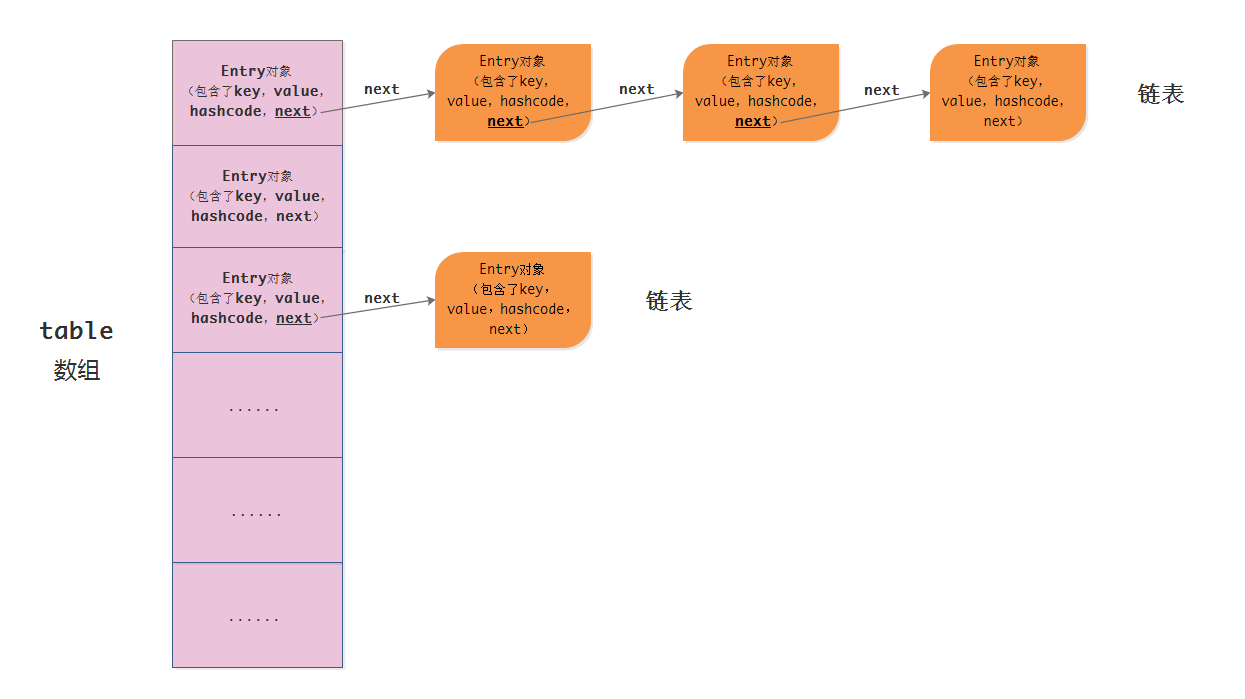
当我们把一个键值对存进 HashMap 时,它首先会对键的 hashCode() 进行重新计算,然后调用 indexFor() 方法计算出 table 数组的索引,最后将键值对存放在数组在该索引下的 Entry 对象中。但是,两个不同的键 A 和 B,它们计算出来的索引值有可能是相等的,这样一来就会产生“碰撞”,我们总不能在一个 Entry 对象中存储两个键值对。为了解决碰撞问题,链表的作用就显示出来了 —— 假设 A 和 B 经过计算后得到的索引都是 0,且 A 所在的 Entry 对象已经存在于数组的第一个位置,当 B 所在的 Entry 对象也准备来第一个位置的时候,它会自动链接到 A 所在 Entry 对象的 next 属性上,后续不管 C 还是 D,只要它们的 hashcode 相等,都依次往后链接,这就形成了一个链表。仔细一看,HashMap 维护的数组,里面的成员其实就是链表,链表上存放的才是包含键值对的 Entry 对象。
同理,当我们从 HashMap 中取数据时,会先对传进来的键进行计算得到数组的索引,然后对该索引下的链表进行遍历,如果链表中某个节点的键与传进来的键相等(调用 equals() 方法返回 true),就返回该节点的值。
对了,在 Java 8 当中,链表还有可能是红黑树。事情是这样的,如果一个 HashMap 中的键值对特别多,那么链表中的节点数量就也变得很多,这样一来遍历链表的效率就会大大降低,从而查询效率就降低了,所以为了提高效率,Java 8 引入了红黑树。但并不是没有链表了,只有当一个链表的节点数量大于 8 的时候,才会将该链表转换为红黑树。另外, Java 7 当中的头插法,在 Java 8 中也被改成了尾插法。
HashMap 内部其实还很深,很多东西上面都没提到,或者没有细说。像初始容量(InitialCapacity)、加载因子(loadFactor),影响着 HashMap 的自动扩容等;indexFor() 具体是怎么计算键值对存放的数组索引、从而避免碰撞的;链表是如何转换为红黑树的……后续还需要加深阅读及学习。
HashMap 的实现#
今天简单实现了一下 HashMap,说简单,那是真的简单,感觉快与官方 HashMap 不搭边了😂。代码如下,仅仅是学习 HashMap 过程的笔记,不代表 HashMap 的真正原理……
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| package com.realchoi.collection;
import java.util.LinkedList;
/**
* 自己简单实现 HashMap。
* Hashmap 底层实现:数组 + 链表
*/
public class MyHashMap {
// HashMap 中维护的链表数组(此处暂时将数组大小定为 999)
// 这里直接使用 Java 自带的 LinkedList
private LinkedList[] linkedList = new LinkedList[999];
// 键值对的个数
private int size;
/**
* 往 HashMap 中添加键值对
*
* @param key 键
* @param value 值
*/
public void put(Object key, Object value) {
// 初始化为一个键值对对象
MyEntry entry = new MyEntry(key, value);
// 先根据 key 的 hashcode 找到链表数组的索引,hashcode 可能为负数,转为正数
int index = key.hashCode() < 0 ? -key.hashCode() % linkedList.length : key.hashCode() % linkedList.length;
// 判断当前索引有没有数据,如果没有数据,则新建一个链表存放在该索引下,当前键值对是当前链表的第一个
if (linkedList[index] == null) {
LinkedList temp = new LinkedList();
temp.add(entry);
linkedList[index] = temp;
size++;
}
// 如果当前索引下已经有链表了,将新的键值对添加到该链表的尾部
else {
// 添加之前还需要遍历链表,判断当前 key 是否已经存在,如果存在,则将原 value 覆盖(因为 HashMap 不允许键重复)
for (int i = 0; i < linkedList[index].size(); i++) {
MyEntry e = (MyEntry) linkedList[index].get(i);
if (e.key.equals(key)) {
e.value = value;
return;
}
}
linkedList[index].add(entry);
size++;
}
}
/**
* 通过键获取值对象
*
* @param key 键
* @return 值对象
*/
public Object get(Object key) {
// 首先根据 key 的 hashcode 得到键值对所在链表的索引
int index = key.hashCode() < 0 ? -key.hashCode() % linkedList.length : key.hashCode() % linkedList.length;
// 然后根据索引找到所在的链表
LinkedList list = linkedList[index];
// 遍历链表,得到值对象
for (int i = 0; i < list.size(); i++) {
MyEntry e = (MyEntry) list.get(i);
if (e.key.equals(key)) {
return e.value;
}
}
return null;
}
/**
* HashMap 中键值对的个数
*
* @return
*/
public int size() {
return size;
}
}
/**
* 键值对
*/
class MyEntry {
// 键和值
public Object key;
public Object value;
// 构造方法
public MyEntry(Object key, Object value) {
this.key = key;
this.value = value;
}
}
|
参考资料#
1、Java 中常见数据结构 Map 之 HashMap
2、HashMap 之元素插入